
Muy buenos días y Bienvenidos a inteligencia artificial, el podcast donde hablamos del presente y el futuro de la inteligencia artificial, analizamos casos donde ya se están usando estas tecnologías y vemos como podemos aplicarlo en el día a día de nuestros trabajos, proyectos y empresas.
Yo soy Pocho Costa, ingeniero en sistemas, programador y amante de la tecnología, y me podes encontrar en pochocosta.com donde ahí también vas a encontrar las notas del programa y otros medios para ponerte en contacto conmigo.
EMPEZAMOS!
Hola a todos y todas! Muchas gracias por estar acá de nuevo, y gracias a todos los que se animaron y enviaron sus comentarios en el episodio pasado por el sitio web, en Ivoox y también en Twitter. Quedó muy claro que vamos a ir mezclando episodios de novedades con algunos más teóricos. Así que genial! Me gusta que estemos en contacto para que al podcast le vayamos dando forma entre todos.
Además le quiero agradecer al usuario IsaacMv que dejó un muy buen comentario en Ivoox y es que en el episodio pasado hablamos de Machine Learning basado en árboles de decisión, y para completar la teoría me faltó mencionar que ese tipo de aprendizaje automático pertenece al aprendizaje supervisado. Así que gracias IsaacMv por el aporte y eso da pié a que a futuro hablemos de los tipos de aprendizaje automático, lo dejo anotado para más adelante!
Inteligencia Artificial vence a profesionales al StarCraft
Y ahora si, metámonos con el tema del día, que es que hace unos días atras se hizo público que la empresa de inteligencia artificial DeepMind de Google, había logrado ganar 10 partidas de StarCraft a dos jugadores profesionales! Y suma así un nuevo juego a su lista de logros. Porque está empresa ya había logrado ser imbatible jugado al Ajedrez, al Go y al Shogi (que es el ajedrez japonés). Pero esto de StarCraft es algo impresionante, por la complejidad que tiene el juego.
Para los que no lo conocen, StarCraft es un videojuego de estrategia en tiempo real lanzado en 1998 que consiste en utilizar una de las tres razas que tiene (los Zergs, los Protoss o los Terran) y combatir en un territorio para dominarlo. En una partida cada jugador empieza con una serie de unidades de trabajo, que producen recursos básicos que sirven para construir más unidades y estructuras y crear nuevas tecnologías. Y a su vez permiten cosechar otros recursos, construir bases y estructuras más sofisticadas y desarrollar nuevas capacidades que se pueden usar para atacar al oponente.
Ahora bien, estas partidas pueden llegar a durar una hora y durante ese tiempo hay que tener una estrategia de corto plazo y otra de largo plazo, hacer miles de movimientos, gestionar recursos y unidades individualmente, sin contar con que hay que manejar situaciones inesperadas porque no sabes cuando el oponente te puede venir a atacar. Realmente es muy muy complejo jugarlo y por eso es asombroso lo que han logrado.
Si bien ya existían agentes de inteligencia artificial que habían logrado ganarle a los bots de StarCraft en máxima dificultad, es la primera vez que una inteligencia artificial le gana a humanos! A dos jugadores profesionales…realmente impresionante!
Resulta que el 19 de Enero pasado, la empresa DeepMind enfrentó a este programa de inteligencia artificial al que llamaron AlphaStar con dos jugadores del equipo Liquid, Dario Wünsch apodado “TLO” y a Grzegorz Komincz apodado “MaNa” en dos torneos de 5 partidas de 1 contra 1. AlphaStar jugó 5 partidas contra cada uno en el mapa Catalyst LE y el resultado fue un rotundo 5 a 0 contra ambos jugadores. Con la única restricción de que tanto AlphaStar como los jugadores tenían que usar la raza Protoss. En este juego cada raza tiene diferentes características, y por lo general cada jugador tiende a especializarse en una de las razas. Y para reducir el tiempo de entrenamiento AlphaStar lo que hicieron fue entrenarla solo con Protoss.
Esta información fue publicada en el blog de DeepMind el 24 de Enero pasado junto con un video de demostración de casi 3 horas subido a YouTube. Les dejo los enlaces en las notas para los que tengan tiempo de verlo.
Los desafíos de dominar el StarCraft
Lo que comentan los de DeepMind en su blog es que para dominar este problema tenían que hacer avances en 5 desafíos de investigación de la inteligencia artificial.
El primero es la teoría de juegos, porque al igual que cuando jugas a piedra papel o tijera no hay una “mejor estrategia” un proceso de capacitación en inteligencia artificial necesita explorar y expandir continuamente las fronteras del conocimiento estratégico.
El segundo desafío es que a diferencia de juegos como el ajedrez donde ambos jugadores ven todo el tablero, en StarCraft cada jugador tiene que ir explorando activamente el mapa para descubrir información que es clave.
El tercero era la planificación a largo plazo, ya que por lo general el efecto de una acción puede no ser inmediato y que hagas algo que parece que no vale la pena hasta mucho tiempo después.
Otro de los desafíos es que es un juego en tiempo real, y no es como un juego de mesa donde los jugadores van alternando movimientos por turnos. Acá están ambos jugadores haciendo cosas TODO EL TIEMPO!
Y por último que hay que manejar a la vez cientos de unidades y edificios, lo que hace que la combinación de posibilidades sea altísima!
Y bueno para ayudar a la comunidad a explorar más estos temas DeepMind y Blizzard trabajaron en conjunto y lanzaron un conjunto de herramientas de código abierto llamado PySC2 que incluye el dataset mas grande de partidas de StarCraft que se haya publicado. Les dejo el enlace en las notas del programa para los que les interese.
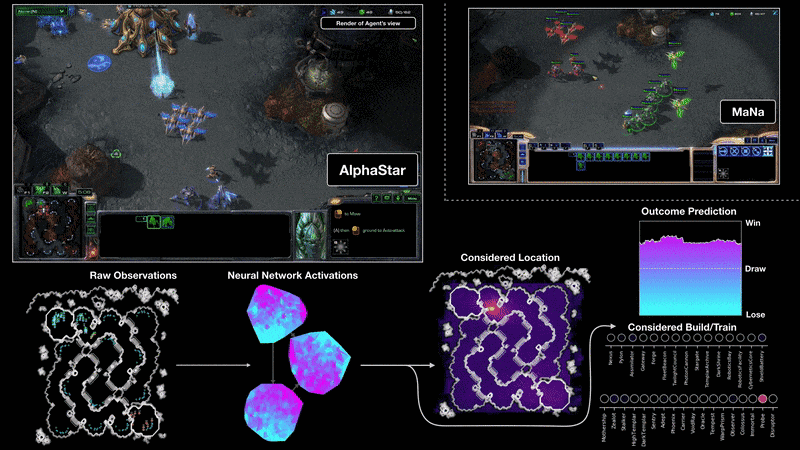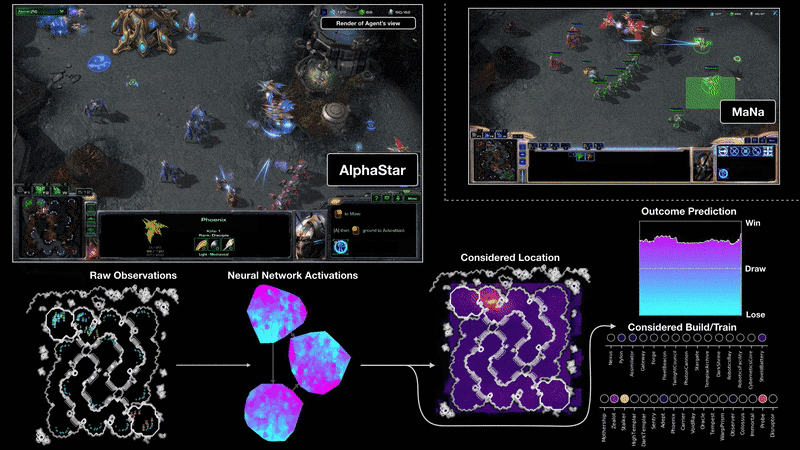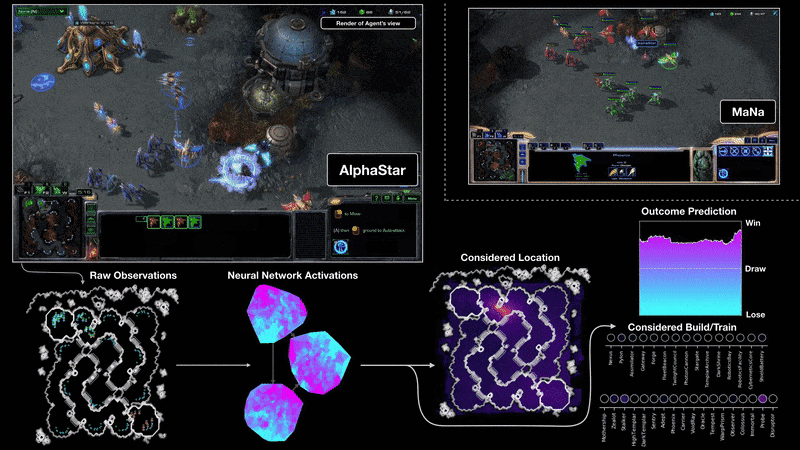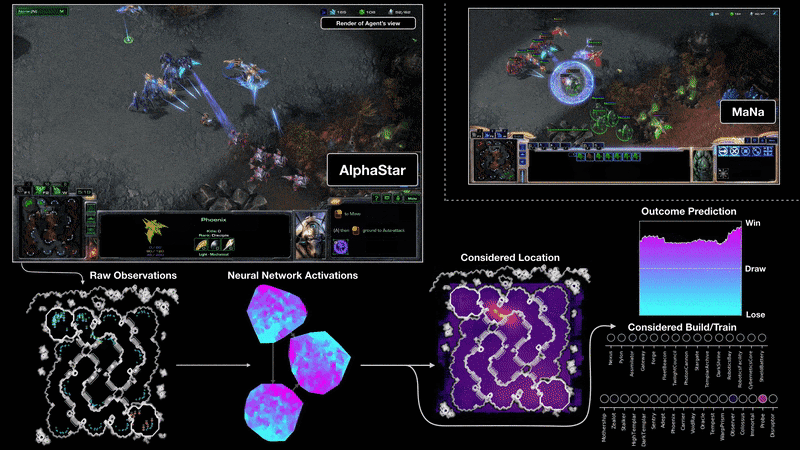
Como entrenaron a AlphaStar
Bueno, ahora veamos como trabaja todo eso?
AlphaStar consiste en una red neuronal profunda que se entrena a partir de una entrada de datos. Esta entrada de datos es cada fotograma del juego, como si fuera una captura de pantalla de cada momento. Y esto es lo que usa para predecir la secuencia de acciones esperada usando aprendizaje supervisado primero y aprendizaje por refuerzo después.
O sea, primero se la entrenó por aprendizaje supervisado mostrándole repeticiones de partidas de humanos y por imitación aprendió cómo administrar los recursos y cómo controlar las unidades individuales.
Después con aprendizaje por refuerzo fueron creando nuevas instancias del agente que jugaran entre si, y en cada iteración creaban nuevas que aprendieron de las anteriores.
Y bueno a medida que las partidas avanzaban y se creaban nuevos agentes iban surgiendo nuevas estrategias que derrotaban a las anteriores.

¿La frutilla del postre? En 14 días cada agente experimentó 200 años de juego usando 16 TPU por cada agente. TPU son unos procesadores especiales de Google usados para procesar instrucciones de machine learning muy muy rápido.
Pero ojo, esto no quiere decir que AlphaStar jugara más rápido que los humanos, de hecho la cantidad de acciones por minuto que hizo AlphaStar fue menor a la que hicieron MaNa y TLO. Porque tiene un retraso de 350 milisegundos entre que observa y ejecuta la acción. O sea que el resultado no se se debió a que AlphaStar sea mas rápida sino a que tomó mejores decisiones durante el juego.
¿Qué dijeron los jugadores?
TLO dijo que el agente ejecutó estrategias que a él nunca se le había ocurrido. Y Mana dijo que le sorprendió que el agente haga movimientos avanzados y estrategias diferentes en cada partido. Y que le hizo dar cuenta que su juego estaba basado en forzar errores del rival y saber explotar la reacción que tenía el oponente ante esos errores.
Y bueno hasta acá el programa de hoy, espero que les haya gustado este episodio y los anteriores y si es así que se animen a pasar por iTunes o Ivoox a dejar una reseña que venimos medio estancados con eso, y como saben eso es lo que ayuda a que este podcast tenga más visibilidad y pueda crecer, ya que eso es lo que va a hacer que a futuro podamos tener cada vez mejores episodios y sea mejor para todos!
Y después del mangazo, ahora si, nos escuchamos en el próximo episodio donde seguiremos hablando de este hermoso mundo de la inteligencia artificial.
Deja una respuesta