

Buenas buenas! ¿como andan? espero que muy bien! Acá estamos de vuelta con un nuevo episodio del podcast Inteligencia Artificial y hoy quería dedicar el episodio a hablar de las tecnologías que hay por detrás de ChatGPT y explicar un poco algo que me preguntan mucho y que es tan sorprendente, ¿no?, que hoy a varios meses de su lanzamiento sigue pareciendo increíble como funciona ChatGPT. Así que quería dedicar un episodio completo a este tema ya que hemos hecho episodios hablando de cómo funcionan algunas tecnologías como las redes neuronales o las redes convolucionales pero de transformers por ejemplo nunca hablamos en profundidad…creo que la vez que mas hablamos de NLP fue cuando vino Omar Sanseviero de Hugging Face, así que me parecía un buen momento para tocar el tema.
Pero antes de empezar quería aprovechar para agradecer por los comentarios que dejan en Spotify y por la pregunta que respondieron sobre la frecuencia de publicación del podcast, realmente les agradezco muchisimo!
También aprovechar para agradecer a la gente de Mexico que se re coparon con el podcast y lo pusieron #1 en la categoría Tecnología de Spotify durante varios días y creo que se sigue manteniendo en el Top 5 de la categoría desde hace bastante y eso es un montón la verdad, asi que queria agradecerles porque cuando empecé con este podcast a finales del 2018 nunca pensé que lo iban a terminar escuchando tantas personas, así que si esto sigue es gracias a uds que lo escuchan, que me escriben y que hacen que me den cada vez más ganas de grabar episodios.
Y hoy particularmente la idea es hacer un episodio un poquito técnico y hablar de cómo es que funcionan los modelos como ChatGPT, que es algo que me preguntaron varias veces y me parecía que estaba bueno aprovechar el espacio y comentarlo.
La verdad que funciona tan bien que me siguen sorprendiendo los resultados, y viajando en el tiempo con la imaginación unos años atrás era impensado que en 2023 íbamos a tener algo así. Pero bueno hay una sumatoria de tecnologías que se fueron mezclando para llegar a estos resultados y una de esas son los embeddings.
Así que empecemos explicando de forma simple que son los word embeddings. Y básicamente son la forma de representar las palabras como vectores de números.
Entonces imaginemos que cada palabra del diccionario es un punto en un espacio de muchas dimensiones. Y cada una de esas dimensiones representa algo de esa palabra, como puede ser el género, el idioma, si es un verbo, un artículo, y así sucesivamente.
Eso al estar representado en forma de vectores de números hace que las máquinas puedan hacer operaciones como sumas, restas y cálculos de distancias, y eso se traduce en que las máquinas puedan entender las relaciones entre las palabras de una mejor manera, como por ejemplo entender que gato y perro son más similares que perro y automóvil por ejemplo.
De acá es de donde sale la ecuación que se hizo muy famosa de Rey – Hombre + Mujer = Reina. Que describe bastante bien lo que se puede hacer con los word embeddings.
Así que bien, de forma resumida podríamos decir que eso que dijimos recién son los word embeddings y que son una tecnología muy importante para el procesamiento de lenguaje natural y que juega un papel súper importante en modelos del lenguaje como ChatGPT.
Agrego también que algunos de los modelos de word embeddings más conocidos son Word2Vec, GloVe o FastText.
Entonces ahora que sabemos que son, veamos cómo se generan.
Básicamente, Word2Vec o cualquiera de estos modelos necesitan ser entrenados con un gran corpus de texto, entonces con esto por ejemplo se puede aprender a predecir una palabra en una oración en base a las palabras que la rodean. Ya que a medida que recorre el corpus de texto empieza a ver que hay ciertas palabras que suelen aparecer en los mismos contextos. Por ejemplo, que las palabras gato y perro aparecen en contextos similares. Por lo que tendrían significados similares y por eso les asigna vectores similares.
Entonces podemos decir que los embeddings capturan la semántica de las palabras y si las palabras tienen significados similares también van a tener embeddings similares, y además van a tener capturadas relaciones. Como la relación de género entre rey y reina o la relación de cantidad entre perro en singular y perros en plural, y eso se puede ver reflejado si graficas los vectores en la dirección o distancia.
Yo les voy a dejar en las notas un par de capturas de unas pruebas que hice con palabras para que vean como usando el modelo word2vec a través de la librería gensim le fui dando pares de palabras y le pido que me devuelva un índice de similaridad.

O le doy también dos palabras y le pido que me devuelva el top 5 de las palabras más similares a estas, entonces por ejemplo le doy las palabras rey y reina y me devuelve monarquía, princesa, príncipe y así.
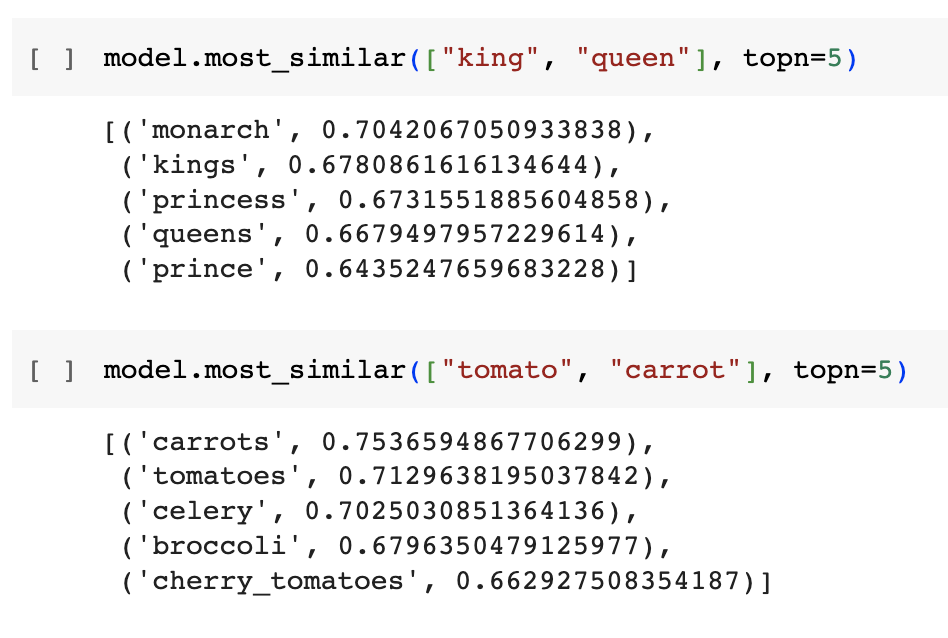
Claramente estas son pruebas que le haces al modelo para ver que tanto tiene embebido el entendimiento del lenguaje, y como vemos tienen mucho, por lo que los word embeddings terminan siendo una pieza fundamental del NLP para muchas tareas como puede ser traducir o generar texto y también para herramientas como ChatGPT.
Entonces bueno, ya hablamos de los embeddings, ahora hablemos de otro concepto fundamental del NLP que son los transformers, que es un tipo de arquitectura de aprendizaje profundo que digamos que revolucionó el campo del NLP desde que se publicó su primer paper llamado “attention is all you need” en el año 2017, y que a partir de ahí por ejemplo Google lo empezó a usar en su buscador, se usa en GPT-3, ChatGPT y básicamente para todos los grandes modelos de lenguaje que se implementan hoy en día.
Y esta arquitectura fue revolucionaria porque antes en NLP se venía trabajando con redes neuronales recurrentes, o redes LSTM y estas trabajan procesando las palabras de una frase de manera secuencial y el problema con esto es que se pierde la relación entre palabras que estén alejadas.
O sea que cuando llegaban a las palabras del final de la oración capaz que ya habian perdido el hilo de lo que decía al principio.
La innovación de los transformers es que implementan un mecanismo de atención y que procesan toda la frase al mismo tiempo encontrando a qué palabras de la frase le tienen que dar más relevancia. De ahí lo de Attention is all you need.
Algo mas para mencionar sobre la arquitectura de los transformers y que son parte de la innovación que los diferencia de lo que se venia haciendo antes es que en la arquitectura tienen un codificador y un decodificador y cada uno de estos en una de sus capas implementa este mecanismo de atención que les mencionaba antes.
El codificador es el que toma la frase de entrada y tiene que “entenderla” entre comillas y el decodificador es el encargado de generar la salida.
La verdad es que no me voy a meter en mayor profundidad hablando de los transformers acá en este audio porque para la mayoría va a ser aburrido, eso lo pueden buscar y encontrar bien explicado en montones de sitios en internet, y tampoco es la intención de este episodio, pero ya habiendo mencionado word embeddings y transformers lo que falta decir es que lo que ingresa en el codificador en realidad son los embeddings de la frase de entrada.
O sea el primer paso es recorrer todas las palabras y transformarlas en embeddings para pasarlas todas juntas al codificador en un formato numérico como para que las pueda procesar.
Bueno ya dijimos que son los transformers, entonces para seguir avanzando veamos que es GPT, que es una sigla que significa algo así como Generative Pre Trained Transformer o Transformer generativo pre entrenado.
O sea que es un modelo transformer pre entrenado para que su salida sea generativa, y es de propósito general. Y específicamente OpenAI que es quien lo hizo, lo entrenó con inmensas cantidades de texto de internet, por lo que como vemos su resultado es brutal.
No se si se acuerdan que en el 2019 hice un episodio cuando salió GPT-2 que no querían compartir el modelo porque era peligroso. Y ese modelo no le llega ni a los talones a GPT-4 así que la verdad es que impresionante lo que se avanzó en los últimos años con esto. Y por las dudas aclaro, lo de GPT-3 o GPT-4 tiene que ver con la versión del modelo, que le van aumentando el número a medida que lo mejoran.
Pero bueno retomemos, GPT lo que hace es completar texto entonces si le damos una oración incompleta por ejemplo que diga “hoy es un día” GPT va a agregar algún texto que tenga sentido y que sea coherente con lo que pusimos y por ejemplo podría agregar una parte y que la frase quedaría “hoy es un dia hermoso para salir a pasear”.
Y lo interesante es que GPT no hay una única respuesta correcta y si repetimos esto muchas veces va a ir generando distintas respuestas que tengan sentido.
Y todo eso lo hace como dijimos antes, agarra el texto que pusimos lo convierte en embeddings, lo pasa por el codificador por la capa de atención, después del decodificador y genera los embeddings de salida y acá hace la inversa que al principio y tiene que transformar esos embeddings en palabras. Y eso sería en líneas generales más o menos así como trabaja. Aclaro que los transformer tienen arquitecturas más complejas que esto y pueden tener distintas cantidades de capas pero para fines didácticos lo simplificamos un poco.
Entonces ahora sí pasemos a ChatGPT, que es una versión del modelo GPT pero que tiene hecho un fine tuning, digamos como que está entrenado especialmente con conversaciones. O sea que como base se usa GPT pero se le hace como un segundo entrenamiento con conversaciones. Si les interesa entender más cómo es esto del segundo entrenamiento pueden buscar un episodio que se llama Transfer Learning que es y para qué sirve. Les dejo el link en las notas por si después lo quieren ir a escuchar.
Y bueno creo que ahí ya comentamos cuales son las tecnologías, modelos y arquitecturas que hay por detrás de ChatGPT, y aunque todavía me sigue pareciendo increíble lo que se puede hacer con ChatGPT así es como trabaja por dentro.
Parece magia pero me hubiese encantado de chico en la escuela haber sabido que para lograr algo así se necesitaban los vectores y las matrices de números, y hoy mismo no se si ya se estará hablando de la inteligencia artificial o chatgpt en clase. Sería genial si alguien que esté escuchando esto esté en educación y me pueda contactar para compartirnos que se hace con todo esto en los colegios actualmente, sería fantástico saberlo, porque no podemos no estar preparando a la juventud para vivir con esto.
Así que nada, tiro esa botella al mar y a ver si alguien la levanta y vemos que pasa con todo esto, que es algo de lo que deberíamos ocuparnos, me parece.
Y bueno, con eso llegamos hasta el final de este episodio, y como siempre les agradezco por haber llegado hasta acá y les pido que si les gustó lo compartan con quien crean que pueda interesarle, suscribanse tambien si todavía no lo hicieron en la plataforma donde sea que estén escuchando y si pueden dejar una reseña de 5 estrellas en spotify o apple podcast eso ayuda a que el podcast llegue a mas personas.
Y con respecto a la pregunta sobre la frecuencia del podcast que les hice en el episodio pasado en Spotify ya tomé nota sobre las respuestas y voy a ver si puedo llegar a crear la cantidad que me piden pero la verdad es que voy a necesitar dedicar toneladas de tiempo así que tal vez necesitemos conseguir algun sponsor para el podcast o algo por el estilo, así que si conocen alguna empresa que este interesada en apoyar esto que hacemos ponganlos en contacto a ver si me pueden a ayudar a poder entregar mucho mas valor de forma gratuita!
Y nada, por otro, lado como recibo un montón de correos y mensajes con preguntas y pedidos, seguramente vaya a estar organizando un video Youtube o un directo, o en Instagram o twitter, habrá que ver donde, así podemos responder y profundizar en cosas para los que tengan interés en esas cuestiones que más me preguntan.
Así que también voy a dejar en las notas una cajita para que me dejen un medio de contacto así les aviso cuando esté haciendo esas actividades y tal vez para comentar algunas otras novedades.